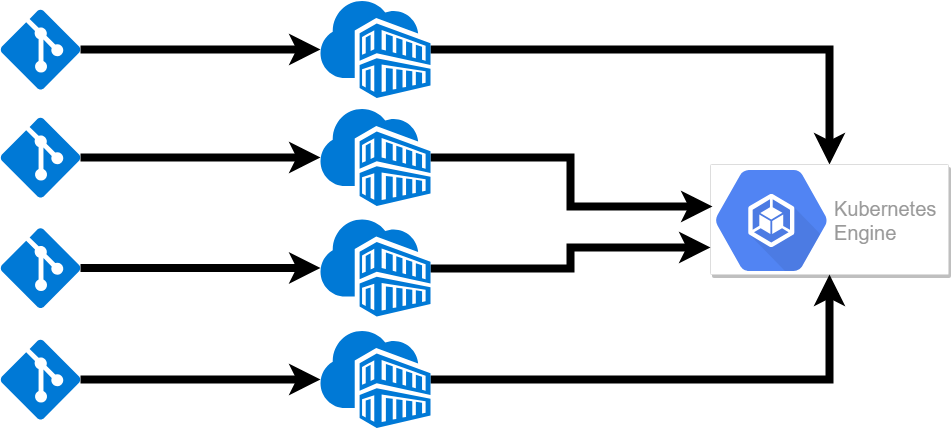
As the internet and technology continue to permeate every business function, tech leads are becoming key decision makers. Companies are leaning on technology to create innovation, minimize costs through efficiency, and most importantly to drive revenue growth. As a result, companies are seeking out new software and capabilities, but buying